某家啤酒廠想在灌裝前檢查產線上的鋁罐有無凹痕或破損,因為罐身凹痕可能會損害內部塗層,使高pH值的啤酒接觸到裸露的鋁、進而導致口感變差,此時只使用單支相機搭配廣角鏡頭、環形光源架設系統,從產線上方俯拍,就能拍到罐頭內部的完整影像,確認有無破損。

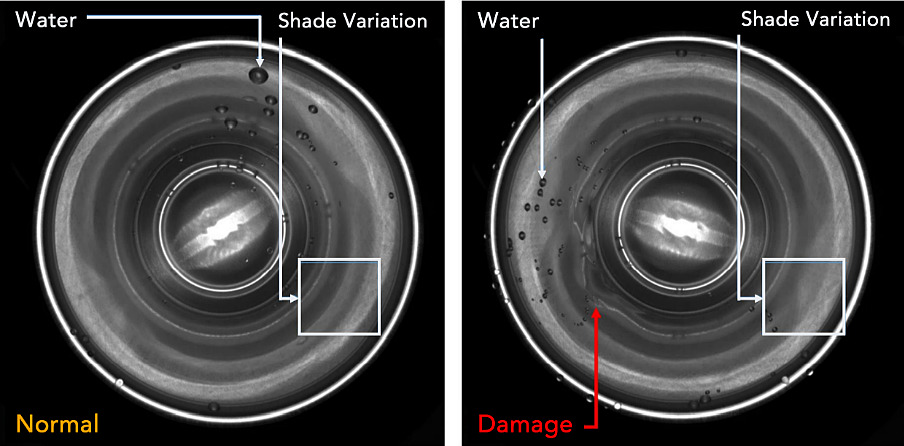
從拍攝影像能看出罐頭內部是否有凹痕及破損,但罐身的紋路起伏跟水滴會導造成影像產生雜訊,讓檢查難度上升。

傳統的機器視覺檢測法在忽略罐身表面及水滴等雜訊的同時,也會導致難以辨識罐頭瑕疵。AI的分類演算法(Classification)能夠幫助我們精準比較、辨識出被雜訊影響的正常零件、以及實際的瑕疵品。
Classification是一種深度學習模型,經過訓練之後能將單一影像分類至一或多個類別。傳統的機器視覺分類法會根據測量結果及規則,來判斷影像是否合格;而AI的深度學習模式,則是以合格、不合格的樣本影像訓練模型,讓模型學習之後能夠判斷影像屬於哪個類別。只要樣本涵蓋的情境夠廣,就能成功訓練模型在忽略雜訊同時,還能正確地分類影像。本文案例中使用的模型,將把影像分為正常罐頭、破損罐頭兩個類別。
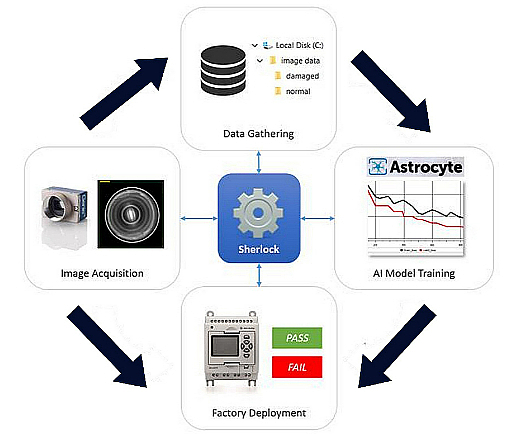
這個案例中我們以Sherlock視覺軟體和Astrocyte AI訓練軟體相互搭配,開發出點到點、免寫程式,能夠快速部署的AI模型。Sherlock能連接相機、拍攝影像、運行推理、判定正常/瑕疵決策,以及連接廠端硬體。易於上手的Astrocyte深度學習軟體,則可讓使用者輕鬆訓練並驗證 AI模型。
想開發一個成功的深度學習應用程序?關鍵就是建立一個能夠訓練模型的學習數據集;而建立高質量數據集的第一步,就是讓數據涵蓋製程裡所有可能出現的變異、並且定義出合格/瑕疵的範圍。通常,我們會把這個步驟稱為「缺陷分類與定義」。在這個案例中,罐頭有各種可能的瑕疵形式,比如小的凹痕、表面波紋、或者嚴重擠壓損毀等等,因此我們必須分別辨識、並定義這些瑕疵。
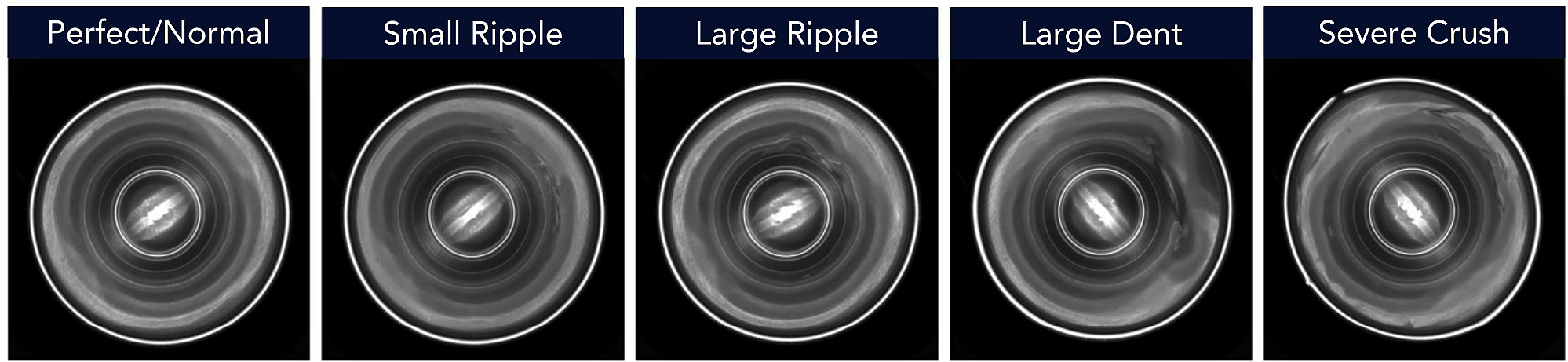
先辨識並定義製程中可能出現的瑕疵,能確保我們在收集數據及訓練AI模型的後續步驟中,使用的訓練數據具有足夠的代表性。
如果跳過分析及定義瑕疵的步驟,有可能導致訓練完成的模型只能辨識出一種特定的缺陷型態。舉例來說,我們建立了一個只包含表面大波紋瑕疵的學習數據集,模型在訓練階段表現良好,但當部署到正式環境時,卻無法辨識較小波紋、大凹痕、嚴重擠壓毀損等其他類型的瑕疵,而我們很可能對模型的缺陷毫無所察。
值得注意的是,深度學習的分類模型無法用來判斷瑕疵的嚴重性。在這個應用案例中,如果我們只針對表面較大的波紋進行訓練,那模型就有可能辨識不出大凹痕、或嚴重擠壓損毀等定義中較為嚴重的缺陷。這個模型只能夠辨識出它被訓練的影像。
在收集數據時,請務必使用與產線相同的相機、鏡頭、光源,在一樣的條件下取得影像資料。您也可依照實際需求,規劃收集額外的影像資料。如果模型訓練已經達到精度上限,通常提高精度的唯一方法,就是在數據集裡添加更多影像樣本。
收集到足夠多的影像資料,對於訓練及驗證模型非常重要,比較合理的樣本數是1000張以上的影像,但在許多情況中往往很難取得這麼多樣本,所以我們常常必須發揮創造力,從少量的樣本衍伸出更多數據。在這個案例中,我們以100個樣本建立模型,並且加入不同乾濕度、旋轉或不同視角等變因取像,以創造足夠多的樣本數,模擬實際的生產環境。
| Taxonomy | Numbers of Samples | Dry Images | Wet Images | Total Images |
| Perfect/Normal | 68 | 270 | 540 | 810 |
| Small Ripple | 10 | 40 | 80 | 120 |
| Large Ripple | 10 | 40 | 80 | 120 |
| Large Dent | 10 | 40 | 80 | 120 |
| Severe Crush | 2 | 8 | 20 | 28 |
Sherlock讓使用者只需點擊、拖曳即可把指令加入工作序列,或加入算法、變量及條件,不寫任何程式就能建立機器視覺程序,設計出可以自動決策的解決方案。Sherlock 能夠相容於所有Teledyne相機、及許多第三方相機。在這個案例中,我們用Teledyne DALSA 5MP Genie Nano相機取像:先建立一個簡單的數據收集程序,然後把影像依照樣本編號及資料增量,存放到不同資料夾。接著,我們在工作區域中定義一個1600x1600的正方形關注區(ROIs)訓練數據,Sherlock會將這個裁剪區域保存到硬碟中。
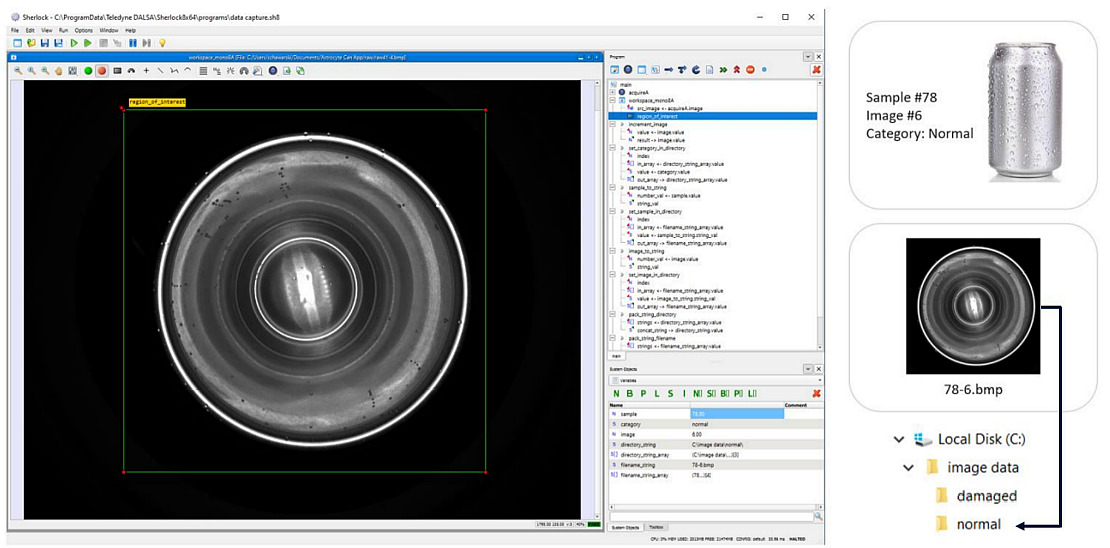
在收集數據跟訓練過程中,把樣本實體對應到影像檔案,並進行標記與分類,能夠幫助我們做進一步的追蹤。如果對影像的分類結果有疑問,就能回溯比對影像跟原始樣本。

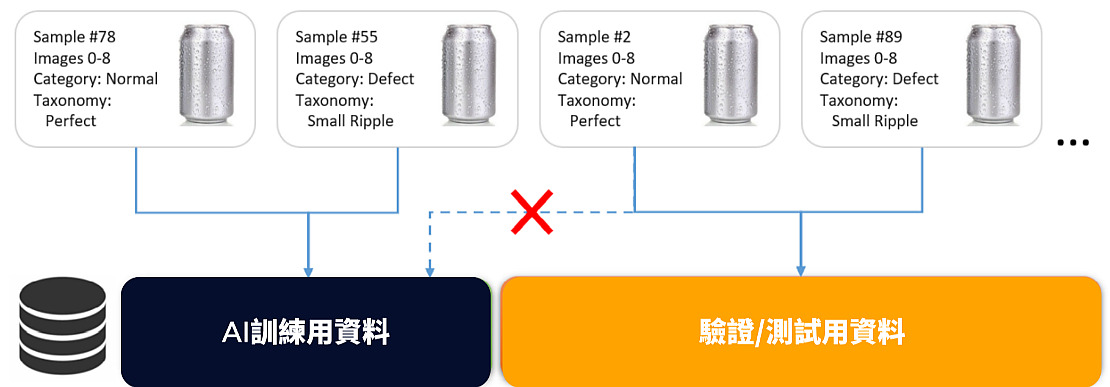
完成數據收集之後,我們會仔細刪除取像不良的檔案、並確認影像是否有被正確辨識為正常跟瑕疵影像。接著,把所有數據分成兩個子集:訓練集、驗證集。Astrocyte會使用訓練集裡的資料來訓練模型、並評估模型的精準度。接著,建立一個獨立於訓練集之外的驗證集,用來檢驗模型是否能正確分類未接觸過的影像。我們以4:6的比例劃分資料,最終產生500張訓練影像,及900張驗證影像,並確保這兩個子集裡的缺陷分布具有足夠的代表性。記得把樣本編碼,才能確保同一個影像不會同時分屬於兩個子集。
這篇文章我們介紹了Sherlock如何收集影像數據,下集將從AI軟體Astrocyte如何訓練AI模型切入,千萬不要錯過!
延伸閱讀:Classification的實機操作